Supervised Learning
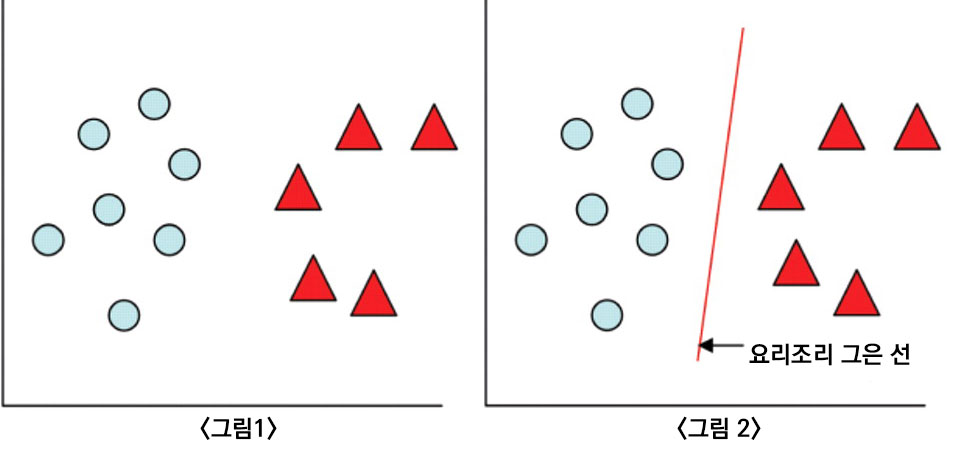
한마디로, 컴퓨터에게 정답이 주어진 데이터셋을 학습시키는 행위이다. 값이 정해진 데이터의 여러가지 요소를 이용한다. 이렇게 그림 1같이 나와 있는 데이터를 요리조리 잘 그어보면 하나의 선으로 나타 낼 수 있는데, 그림 2의 예시와 같은 결과가 나온다. 이런 문제가 Regression Problem(회귀 문제)이고, 이렇게 분석하는 것이 Regression Analysis(회귀 분석)이다.
간단하게 알아보기
컴퓨터에게 사진을 주면 이것이 고양이인지 아닌지 파악해내는 프로그램을 Supervised Learning을 이용하여 구현한다고 하자. 그렇다면 다음과 같은 절차를 거친다.
- 고양이 사진과 개 사진을 엄청 가져다 준다.
- 그리고 무엇이 고양이 사진이고, 무엇이 고양이 사진이 아닌지 알려준다.
- 좀 공부할 시간을 준다.
- 새로운 고양이 사진을 주고 이게 고양이 사진인지 아닌지 물어본다.
여기서, 1번 절차에서 제공하는 사진들이 바로 데이터 셋이고, 무엇이 고양이 사진이고 아닌지를 알려주는 것이 바로 데이터셋에 정답을 부여한다는 것이다.
이미지에 여러가지 요소가 어디 있냐고? 이미지 프로세싱에서 사용하는 영상 특징점이라는 것이 있는데, 그걸 이용한다. 궁금하면 개인적으로 찾아보길 바란다. 이제 좀 더 자세하게 알아보자.
좀 더 자세히 알아보기
자세하게 알기 위해, 좀 덜 직관적일 수는 있어도 표현하기 쉬운 예제를 택했다.
상황 : 현성이가, 공부하기 - 배고파서 밥 많이 먹기. 두가지를 계속 반복하다 종양이 생겼다. 하지만 현성이는 공부를 해야 한다고 이 종양이 암이 아닌 이상 병원에 갈 생각이 없다고 한다. 이것이 암인지 아니면 단순 물혹인지 판단을 하려고 하는데, 의대를 지망하는 우리의 친구 유택이가 물혹과 위 종양의 크기와 환자의 나이를 기록 해 둔 데이터를 가지고 있었다.
X축을 종양의 크기, Y축을 환자의 나이라고 정하자. 이걸 2차원 좌표계에 표현한다면 다음과 같은 그림이 나오게 될 것이다.
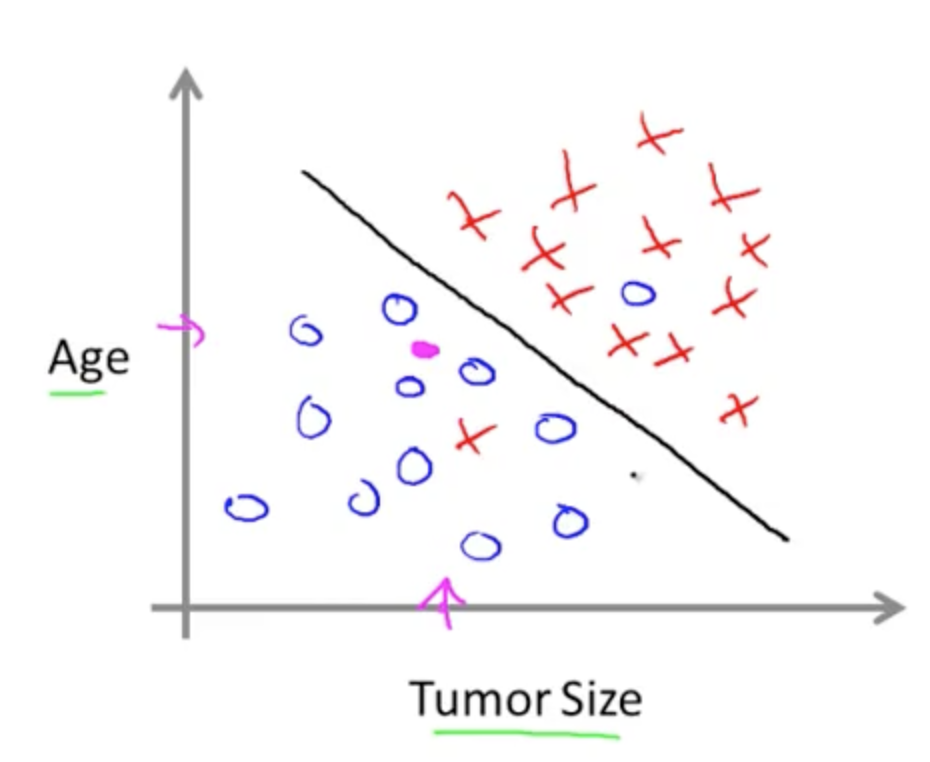
참고, 여기서 O는 암, X는 암이 아닌 물혹이라고 한다.
여기서 요리조리 잘 그은 저 선이 바로 판정 경계이다. 저 선을 기준으로 암인지 아닌지 구분 할 수 있다. 물론, 실제로 학습을 시키려고 한다면 이것보다 더 다양한 요소를 포함하여 계산하여야 한다.
여기서 ==잠시만, 저 X 중간에 있는 O값은 어쩌고?== 라는 질문이 나올 수 있다. 이는 머신러닝이라는 말 자체에 대한 오해가 있는 것이다. 머신러닝은 정답을 제공하는 것이 아니다! 오히려 이 데이터 셋에 완벽히 맞는 분류를 하려고 하면, 이 문제에 대한 일반화를 시킬 수 없는 Overfitting Problem(과적합 문제)가 발생할 수 있다. 위에서 X 중간에 포함된 O나, 그 반대의 경우를 우리는 노이즈라고 명하며, 이를 처리해준 후 계산하기도 한다. 이미지 프로세싱에서는 상기 문제를 해결하기 위하여 가우시안 필터를 적용하기도 한다.